hongkongdoll 最新 陈亦伦:AIR ApolloFM时间全解读
中出辣妹人妻
发布日期:2024-10-13 01:36 点击次数:162
自动驾驶演进历程
回归自动驾驶时间的发展历程,自动驾驶算法栈不错分为三个部分:方针与进攻物、谈路结构、以及决策经营。
现代时间主要挑战
twitter 反差 第一个值得接头的问题在于寰宇模子是否需要被重界说(自动驾驶的寰宇模子和 AI 的寰宇模子界说有所分辨)。自动驾驶中的寰宇模子在之前的架构中代表了感知的输出和决策经营的输入,也决定了感知 AI 的真值标注阵势和决策经营的规章设想阵势。
 与开环为主的感知AI算法比,决策经营因为是闭环系统,监督式的师法学习存在很大挑战。师法学习主要的问题是绝大多数数据皆是正常驾驶数据,而不是危急驾驶数据。学习的关节是怎么样从危急驾驶情状规复到正常驾驶情状。依靠无数司机去遍历顶点长尾漫衍的危急驾驶情状是不现实的。
淌若采用强化学习,则很容易堕入到如何设定奖励函数的泥潭中。后果可能还不如径直设想规章好。
与感知AI 处理的高内聚性的数据漫衍不同,试验决策经营AI难度较高,本体上决策经营的样本漫衍是通过多个智能体和多个场景组合而成,漫衍相配寥落,对小样本学习条款很高,这就条款 AI或者真确联结每个问题和场景,而不是简便操心,不然就会对数据的数目和漫衍条款顶点苛刻。
与开环为主的感知AI算法比,决策经营因为是闭环系统,监督式的师法学习存在很大挑战。师法学习主要的问题是绝大多数数据皆是正常驾驶数据,而不是危急驾驶数据。学习的关节是怎么样从危急驾驶情状规复到正常驾驶情状。依靠无数司机去遍历顶点长尾漫衍的危急驾驶情状是不现实的。
淌若采用强化学习,则很容易堕入到如何设定奖励函数的泥潭中。后果可能还不如径直设想规章好。
与感知AI 处理的高内聚性的数据漫衍不同,试验决策经营AI难度较高,本体上决策经营的样本漫衍是通过多个智能体和多个场景组合而成,漫衍相配寥落,对小样本学习条款很高,这就条款 AI或者真确联结每个问题和场景,而不是简便操心,不然就会对数据的数目和漫衍条款顶点苛刻。
 还有一种处联想路是通过打造仿真器,在仿真器中试验,处理数据数目和漫衍的问题。淌若仿真器富饶真,on-policy的强化学习不错平定超越东谈主类。但当今仿真器「不真」,主要来源于驾驶行径的生成上,反而传感器的仿真(渲染)时间跟着nerf, gaussian-splatting, diffusion等时间普及日渐练习。
还有一种处联想路是通过打造仿真器,在仿真器中试验,处理数据数目和漫衍的问题。淌若仿真器富饶真,on-policy的强化学习不错平定超越东谈主类。但当今仿真器「不真」,主要来源于驾驶行径的生成上,反而传感器的仿真(渲染)时间跟着nerf, gaussian-splatting, diffusion等时间普及日渐练习。
趋势和机遇
当今从工业界的主流决策来看,使用的AI时间主要以2020年以前的AI时间为主。2020年后于今的AI时间发展速率大大陶冶了。事实上,刻下最伏击的AI时间皆产生于2020年之后。如何支配大模子、多模态、生成式、预试验等时间处理自动驾驶行业的中枢挑战,是咱们但愿或者在新架构设想中重心和顺的问题。设想想路
咱们的设想想路领先源自一些基本的想考。
 领先,在洞开路段的自动驾驶是一件极其复杂的任务,举例(如图):要联结新修好的水泥大地开曩昔可能会陷进去,空中震动的塑料袋是否应该消散(消散和不消散皆会存在危急),路上的倒钉是否不错压曩昔,路上的井盖是否盖上了以及怎么处理。另一个例子是骑行者伸出左腿(一般东谈主伸手),其实是在暗意需要向左换谈,以及多样千般造型奇特的红绿灯和交通标记等等。
在洞开场景会碰到相配长的长尾问题,因为自动驾驶是安全经营,每个长尾问题皆不应疏远。一个具备处理如斯复杂任务能力的AI,仍是具备了强东谈主工智能的属性。它需要充分联结附进环境况且或者作念出合适推理。这么的AI不单是会开车,也具备了具身智能的能力。自动驾驶基础模子、具身智能基础模子、通用机器东谈主基础模子本体上是归并个基础模子。换句话说,淌若无法扫尾自动驾驶的AI 模子,很难被称之为具身智能基础模子。
咱们认为这么的基础模子需门径有大讲话模子的能力,因为领先这个模子需要或者感知万物而非感知N物,唯有讲话能装在充分大的类别界说,也即是说基础模子自己就要掌捏富饶大的词汇量,而不是只可容纳有限被界说好的几种类别。其次这个模子需要或者深化学问,而不是通过工程师手写代码输入学问。终末这个模子需要有联结和推理的能力,而非凭借试验集的操心去开车。这三点皆指向了GPT这种大讲话模子的能力。
是以咱们将这么的模子界说为VLA(Vision-Language-Action)模子,分辨于径直的 Vision-Action(VA)模子。VLA模子更接近于东谈主类的大脑响应,需要显式或者隐式的通过东谈主的想考,VA 模子更接近于东谈主类的小脑响应,是不想象索的反射弧式的经过。
从这么的一个VLA大模子起原,然后蒸馏到VA小模子,而不是反过来,是愈加值得探索的主张。
举例东谈主在学习开车的时期,是处在什么皆会,然而不会开车的情状,学习起来很快,开的多了,就会酿成小脑响应,不想象索,开起来不累。这即是一个 VLA缩水到VA 的经过。然而反过来就会极其清贫。试验一个低阶生物开车极其清贫。
第二个想考更偏向工程化。自动驾驶系统算作一个相配强调安全的工业级产物,是需要被正向设想的。它需要有安全的、及时的、能被评释的代码算作安全兜底。尤其是针对一些统统不被允许出现的场景。
领先,在洞开路段的自动驾驶是一件极其复杂的任务,举例(如图):要联结新修好的水泥大地开曩昔可能会陷进去,空中震动的塑料袋是否应该消散(消散和不消散皆会存在危急),路上的倒钉是否不错压曩昔,路上的井盖是否盖上了以及怎么处理。另一个例子是骑行者伸出左腿(一般东谈主伸手),其实是在暗意需要向左换谈,以及多样千般造型奇特的红绿灯和交通标记等等。
在洞开场景会碰到相配长的长尾问题,因为自动驾驶是安全经营,每个长尾问题皆不应疏远。一个具备处理如斯复杂任务能力的AI,仍是具备了强东谈主工智能的属性。它需要充分联结附进环境况且或者作念出合适推理。这么的AI不单是会开车,也具备了具身智能的能力。自动驾驶基础模子、具身智能基础模子、通用机器东谈主基础模子本体上是归并个基础模子。换句话说,淌若无法扫尾自动驾驶的AI 模子,很难被称之为具身智能基础模子。
咱们认为这么的基础模子需门径有大讲话模子的能力,因为领先这个模子需要或者感知万物而非感知N物,唯有讲话能装在充分大的类别界说,也即是说基础模子自己就要掌捏富饶大的词汇量,而不是只可容纳有限被界说好的几种类别。其次这个模子需要或者深化学问,而不是通过工程师手写代码输入学问。终末这个模子需要有联结和推理的能力,而非凭借试验集的操心去开车。这三点皆指向了GPT这种大讲话模子的能力。
是以咱们将这么的模子界说为VLA(Vision-Language-Action)模子,分辨于径直的 Vision-Action(VA)模子。VLA模子更接近于东谈主类的大脑响应,需要显式或者隐式的通过东谈主的想考,VA 模子更接近于东谈主类的小脑响应,是不想象索的反射弧式的经过。
从这么的一个VLA大模子起原,然后蒸馏到VA小模子,而不是反过来,是愈加值得探索的主张。
举例东谈主在学习开车的时期,是处在什么皆会,然而不会开车的情状,学习起来很快,开的多了,就会酿成小脑响应,不想象索,开起来不累。这即是一个 VLA缩水到VA 的经过。然而反过来就会极其清贫。试验一个低阶生物开车极其清贫。
第二个想考更偏向工程化。自动驾驶系统算作一个相配强调安全的工业级产物,是需要被正向设想的。它需要有安全的、及时的、能被评释的代码算作安全兜底。尤其是针对一些统统不被允许出现的场景。
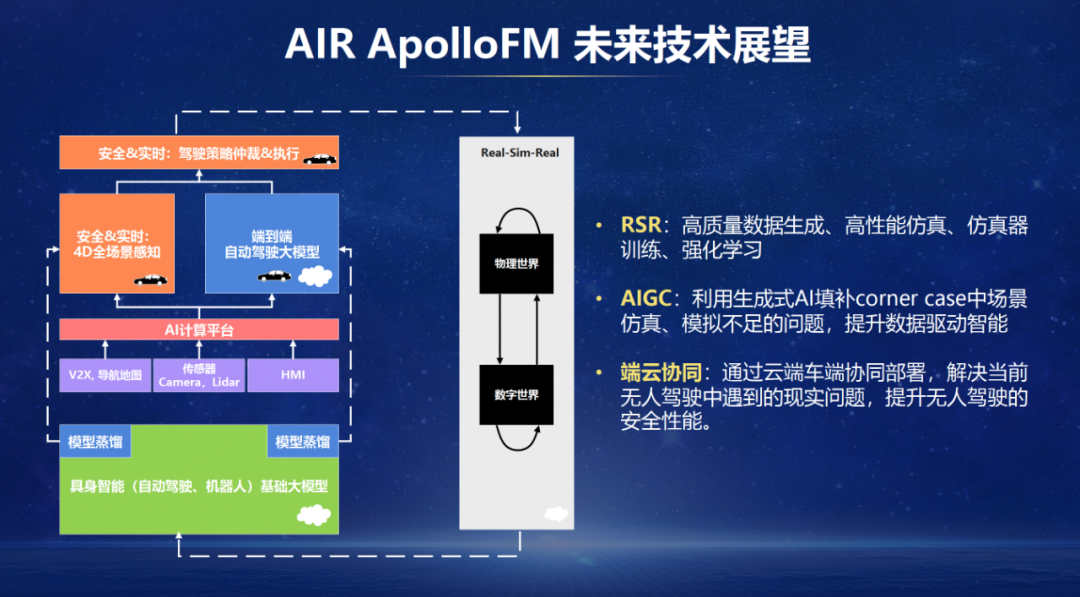
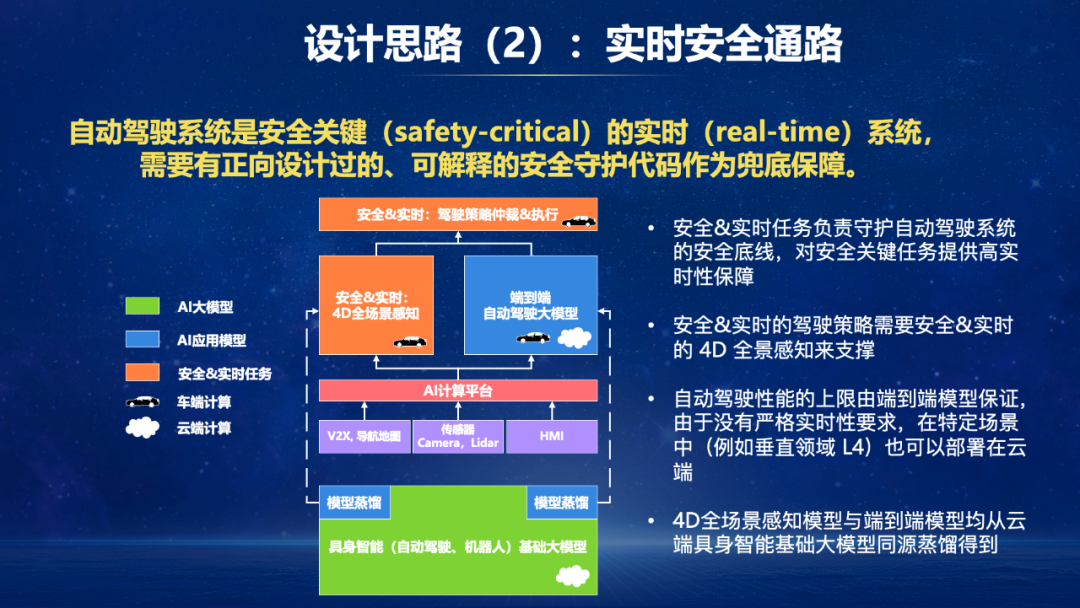 上图中橘黄色代表安全且及时的任务。领先必须存在一个安全且及时的最终驾驶计谋兜底模块。这个兜底模块或者正常责任,就需要获取到寰宇模子中的元素。是以会推导出一个安全且及时的感知模块用来撑持,在这里咱们称之为4D全场景感知。其实即是现代主流的自动驾驶架构,不错兜底特定场景,保阐明时性,然而上限不高。为了陶冶上限,咱们加多了端到端自动驾驶大模子。
启动的两张麇集,4D全场景感知麇集和端到端驾驶麇集,从能力来说皆是具身智能基础大模子的子集。是以这两个麇集从基础麇集蒸馏得到。从具身智能智能基础模子(VLA大模子)蒸馏出端到端驾驶麇集,会带来更高的上限。
这么就推导出了ApolloFM的算法架构。之是以将其起名为ApolloFM,是因为安全且及时模块十分多的扫尾接管了充分打磨过的开源Apollo工程,AI部分由基础模子FM产生,因此称ApolloFM。
上图中橘黄色代表安全且及时的任务。领先必须存在一个安全且及时的最终驾驶计谋兜底模块。这个兜底模块或者正常责任,就需要获取到寰宇模子中的元素。是以会推导出一个安全且及时的感知模块用来撑持,在这里咱们称之为4D全场景感知。其实即是现代主流的自动驾驶架构,不错兜底特定场景,保阐明时性,然而上限不高。为了陶冶上限,咱们加多了端到端自动驾驶大模子。
启动的两张麇集,4D全场景感知麇集和端到端驾驶麇集,从能力来说皆是具身智能基础大模子的子集。是以这两个麇集从基础麇集蒸馏得到。从具身智能智能基础模子(VLA大模子)蒸馏出端到端驾驶麇集,会带来更高的上限。
这么就推导出了ApolloFM的算法架构。之是以将其起名为ApolloFM,是因为安全且及时模块十分多的扫尾接管了充分打磨过的开源Apollo工程,AI部分由基础模子FM产生,因此称ApolloFM。
中枢模块
这部分将重心接头三个主要AI麇集,具身智能基础大模子,以及从它蒸馏繁衍出的4D全场景感知麇集和端到端自动驾驶大模子。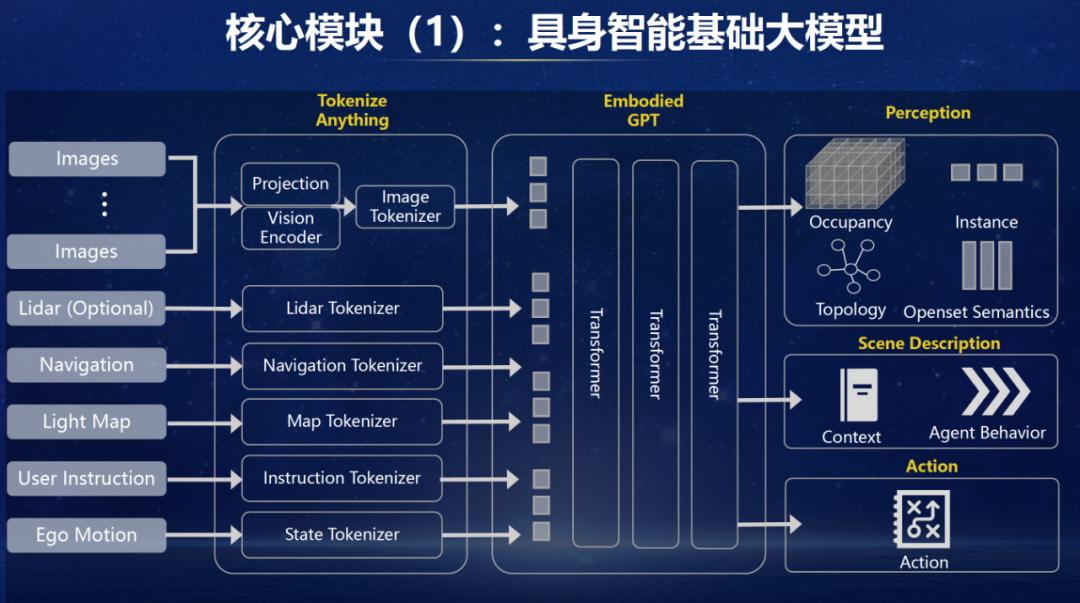 领先是具身智能基础大模子。这个模子的输入和麇集结构比拟访佛于多模态的GPT大模子。它将自动驾驶所有需要输入的信息,举例录像头、激光雷达、导航、舆图(仅需要导航级别舆图,而不依赖高精度舆图)、用户指示、自车位置等信息,皆以token编码的方式插足到预试验过的多模态大模子。这个模子的中枢是模子的输出,因为输出决定了试验和调优阵势。模子的输出被设想为同期输出三种信息。第一种是开集的感知信息,访佛于4D 版块的CLIP;第二种信息是场景花样信息,包括静态场景花样和交通参与者的行径花样,这个信息能有用的监督基础大模子或者真确联结场景和意图;第三个信息是径直输出驾驶action。这亦然一个VLA模子。
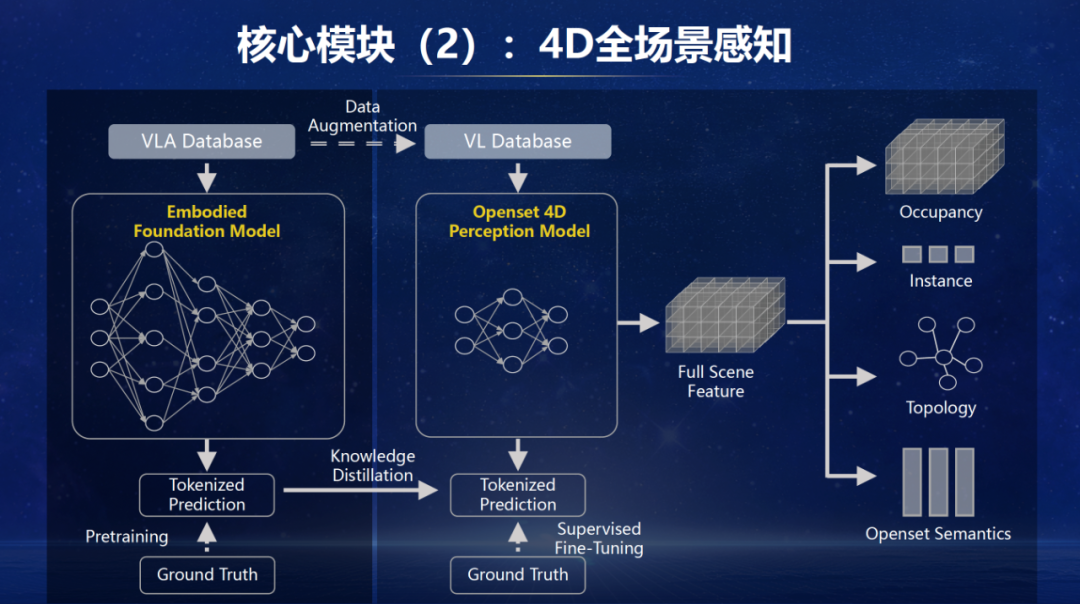
接下来是 4D 全场景感知模子。这个模子在VLA 模子基础上蒸馏成为的一个 VL 模子,同期会欺压算力和麇集结构保阐明时启动。它输出的成分是开集下的寰宇模子(感知万物),包括茁壮抒发、实例化抒发以及之间元素的拓扑关系。
领先是具身智能基础大模子。这个模子的输入和麇集结构比拟访佛于多模态的GPT大模子。它将自动驾驶所有需要输入的信息,举例录像头、激光雷达、导航、舆图(仅需要导航级别舆图,而不依赖高精度舆图)、用户指示、自车位置等信息,皆以token编码的方式插足到预试验过的多模态大模子。这个模子的中枢是模子的输出,因为输出决定了试验和调优阵势。模子的输出被设想为同期输出三种信息。第一种是开集的感知信息,访佛于4D 版块的CLIP;第二种信息是场景花样信息,包括静态场景花样和交通参与者的行径花样,这个信息能有用的监督基础大模子或者真确联结场景和意图;第三个信息是径直输出驾驶action。这亦然一个VLA模子。
接下来是 4D 全场景感知模子。这个模子在VLA 模子基础上蒸馏成为的一个 VL 模子,同期会欺压算力和麇集结构保阐明时启动。它输出的成分是开集下的寰宇模子(感知万物),包括茁壮抒发、实例化抒发以及之间元素的拓扑关系。
 端到端自动驾驶大模子咱们设想了三种模式,不错把柄不同算力和场景部署。
第一种模式是一个充分蒸馏过的VA模子,不再具有L的结构。这么的VA模子的公正是算力条款低,不错作念到及时启动,访佛于东谈主类的小脑。这个模子具备端到端自动驾驶的能力,而且从VLA大模子中蒸馏出的VA模子有更高的上限,是端到端自动驾驶一条相配关节的旅途。
第二种模式是蒸馏出一个中等大小的VLA模子,因为有了讲话模子的存在,有想维链(chain of thought) 的加持,推理能力更强。这个模子是部署在端侧的,不错是异步非及时的。第二种模式下,这个异步的VLA模子与第一种模式的及时VA模子集结使用,十分于端侧的有一定容量的大脑+小脑。
端到端自动驾驶大模子咱们设想了三种模式,不错把柄不同算力和场景部署。
第一种模式是一个充分蒸馏过的VA模子,不再具有L的结构。这么的VA模子的公正是算力条款低,不错作念到及时启动,访佛于东谈主类的小脑。这个模子具备端到端自动驾驶的能力,而且从VLA大模子中蒸馏出的VA模子有更高的上限,是端到端自动驾驶一条相配关节的旅途。
第二种模式是蒸馏出一个中等大小的VLA模子,因为有了讲话模子的存在,有想维链(chain of thought) 的加持,推理能力更强。这个模子是部署在端侧的,不错是异步非及时的。第二种模式下,这个异步的VLA模子与第一种模式的及时VA模子集结使用,十分于端侧的有一定容量的大脑+小脑。
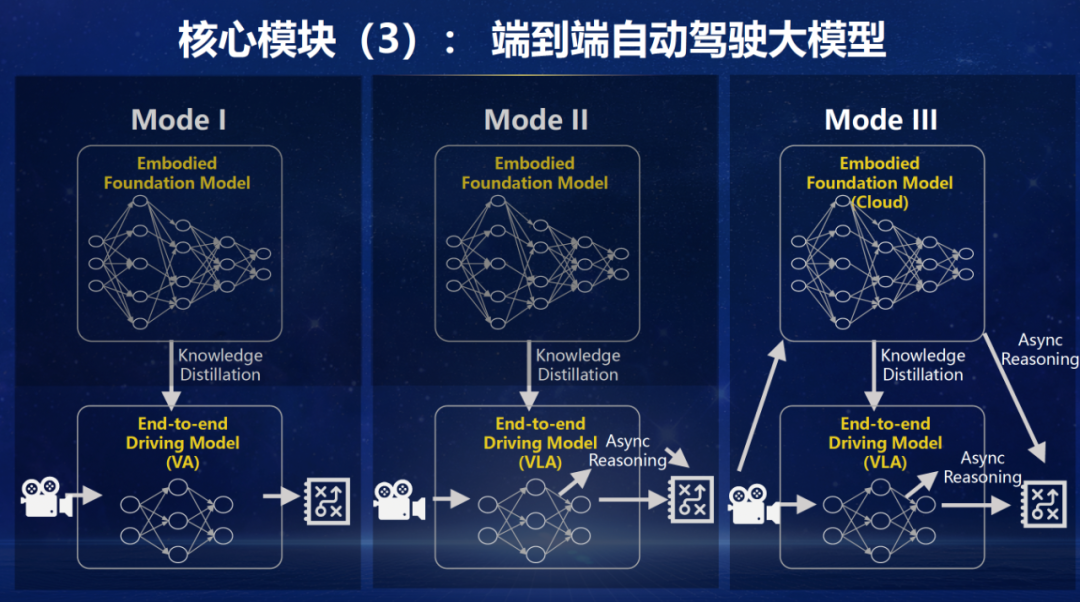 第三种模式是在第二种模式的基础上,加多一个异步的云表大脑,进一步陶冶系统上限。在垂直 L4 的好多领域中,自动驾驶车辆或者机器东谈主是不错联网的,这么不错充分使用云侧的算力和能力。十分于加持了一个云表的超等大脑。
总结下来,第一种模式是一个及时端侧的VA,第二种是及时端侧VA+异步端侧 VLA,第三种模式是及时端侧VA+异步端侧VLA+异步云侧VLA。能力上限从小到大。三种模式的智能性皆源自具身智能基础大模子,保证了整系统的高上限。
第三种模式是在第二种模式的基础上,加多一个异步的云表大脑,进一步陶冶系统上限。在垂直 L4 的好多领域中,自动驾驶车辆或者机器东谈主是不错联网的,这么不错充分使用云侧的算力和能力。十分于加持了一个云表的超等大脑。
总结下来,第一种模式是一个及时端侧的VA,第二种是及时端侧VA+异步端侧 VLA,第三种模式是及时端侧VA+异步端侧VLA+异步云侧VLA。能力上限从小到大。三种模式的智能性皆源自具身智能基础大模子,保证了整系统的高上限。
参考工程设想
算法架构的基础上,研发团队也作念了无数的工程扫尾责任,将上述算法架构部署到实车启动,这里是咱们提供的一个参考工程设想。
拆伙展示
以下视频展示了施行谈路场景中的实车启动拆伙。不错看到ApolloFM或者对附进的场景作念很好的花样,包括领导红绿灯变变色,距离前车过于近, 看到了多个住宅楼来揣度附进可能不少行东谈主,斑马线附进可能会有行东谈主等 。这些信息的获取和使用在之前的时间架构中皆需要耗尽无数的东谈主工规章。 接下来ApolloFM碰到了一个有道理的场景,一辆小轿车在视线被遮掩区准备掉头。ApolloFM推理出了这辆车掉头的意图。底下咱们详备拆解了ApolloFM的想考经过。领先 ApolloFM通过场景联结定位到了需要和顺的两个方针,待掉头车辆和右侧车辆,况且进一步量度出了右侧车辆要汇入本车谈。基于此,ApolloFM在计议了急刹车和车谈内消散两种聘请,合计车谈内微细消散愈加合适,同期VLA中的A部分径直输出了经营轨迹,下发到欺压器,完成了整车谈内消散的动作。这内部值得说起的是,这一系列推理和最终的轨迹输出皆是在AI模子内部完成的。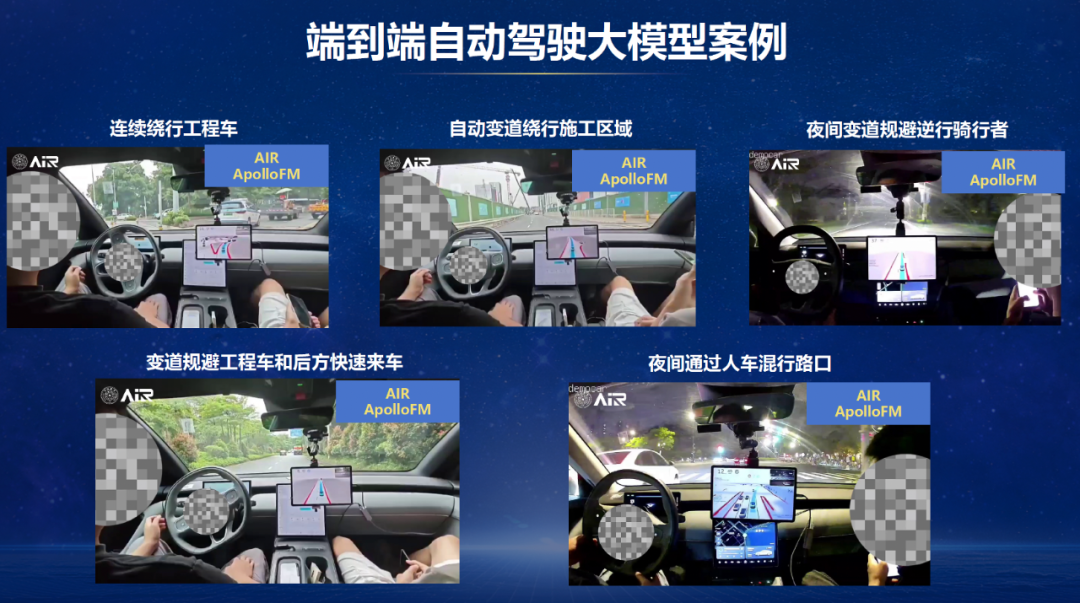
这内部还有好多很有道理的场景,出于事件原因我这里不逐个赘述了。咱们贴出了几个实车视频的案例,包括一语气绕行工程车,自动变谈绕行施工区域,还有一个夜间光照不好,自车主动绕行一个逆行的骑行者,还有一个主动变谈逃避工程车然而被后方车辆逼回,尔后二次变谈得胜的案例;终末的一个是ApolloFM 流流畅过一个比拟复杂的东谈主车混行的区域。这些视频在传统的自动驾驶架构中,均需要好多的规章和代价函数设想和高卑劣的仔细打磨。而在 ApolloFM 中,这些皆仍是被VLA大模子过火蒸馏得到的模子简略的处理了,况且通过融会 ApolloFM 对场景的花样和翰墨推理,如实看到这些是可泛化的拆伙。

AIR ApolloFM 是一个很大的系统工程,除了 AIR 团队除外hongkongdoll 最新,还要罕见感谢这个技俩里的高校成就者分队,接待学术界对此感兴致的训导和同学们经营咱们。